

简单介绍一下Hadoop和Spark异同
Hadoop和Spark两者都是大数据框架,但是各自存在的目的不尽相同,Hadoop和Spark都是并行计算,两者都是用MR模型进行计算,下面为大家详细讲解一下Hadoop和Spark异同。

简单介绍一下kafka常用命令
Kafka是一个分布式、分区的、多副本的、多订阅者,基于zookeeper协调的分布式日志系统(也可以当做MQ系统),常见可以用于web/nginx日志、访问日志,消息服务等等,本篇文章重点为大家讲解一下kafka常用命令。
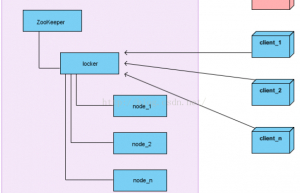
详解zookeeper分布式锁
在我们进行单机应用开发,涉及并发同步的时候,我们往往采用synchronized或者Lock的方式来解决多线程间的代码同步问题。但当我们的应用是分布式集群工作的情况下,那么就需要一种更加高级的锁机制,来处理种跨机器的进程之间的数据同步问题。这就是分布式锁,下面重点为大家讲解一下zookeeper分布式锁。

Linux下安装日志收集系统flume
flume是一个分布式、可靠、和高可用的海量日志采集、聚合和传输的系统,在实际开发环境中被广泛使用,本篇文章重点为大家讲解一下Linux下部署flume具体步骤。
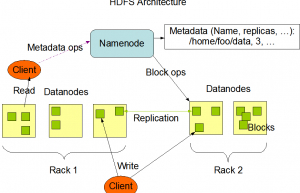
Hadoop分布式文件系统HDFS架构
Hadoop分布式文件系统(HDFS)是一种基于Java的分布式文件系统,它具有容错性、可伸缩性和易扩展性等优点,它可在商用硬件上运行,也可以在低成本的硬件上进行部署。HDFS是一个分布式存储的Hadoop应用程序,它提供了更接近数据的接口。

SparkValue类型的常用算子
Spark之所以比Hadoop灵活和强大,其中一个原因是Spark内置了许多有用的算子,也就是方法。通过对这些方法的组合,编程人员就可以写出自己想要的功能。说白了spark编程就是对spark算子的使用,下面为大家详细讲解一下SparkValue类型的常用算子
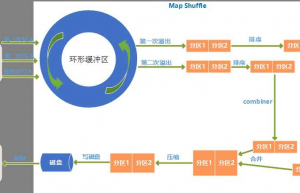
详解MapReduce Shuffle机制
Shuffle过程,也称Copy阶段。reduce task从各个map task上远程拷贝一片数据,并针对某一片数据,如果其大小超过一定的阀值,则写到磁盘上,否则直接放到内存中。

Hadoop —MapReduce 编程思想
MapReduce,本质就是一种编程模型,也是一个处理大规模数据集的相关实现。之所以会有这个模型,目的是为了隐藏“并行计算、容错处理、数据分发、负载均衡”,从而实现大数据计算的一种抽象。

常用的开源数据分析应用软件
我们在本文中介绍了市面上12款顶尖的开源数据分析解决方案,其中一些为大数据分析提供了全面的端到端平台,另一些要与其他技术结合起来。它们都适合大企业使用,都是市面上领先的数据分析工具。

Python中Pandas库绘制数据具体方法
pandas是一个强大的分析结构化数据的工具集;它的使用基础是Numpy(提供高性能的矩阵运算);用于数据挖掘和数据分析,同时也提供数据清洗功能,Pandas 广泛应用在学术、金融、统计学等各个数据分析领域,本篇文章重点为大家讲解一下Python中Pandas库绘制数据具体方法。

.png)
