

PostgreSQL 提供了一些简单的机制使得编写并行算法更加简单。你可以通过使用 ParallelContext 数据结构去唤起后台工作进程、初始化工作进程的进程状态(以匹配唤起他们的后台进程),使进程通过动态共享内存 (Dynamic Shared Memory) 进行通信和写并不复杂的逻辑且不用意识到并行的存在就可以让代码跑在用户后台进程或者任一并行的工作进程。

前言
2016年4月,PostgreSQL 社区发布了 PostgreSQL 9.6,并首次引入了并行查询的能力,进一步释放了多核服务器的计算力。最近微扰酱则因为工作的原因需要调研 PostgreSQL 对并行化算子的实现,就随手翻译了 PostgreSQL 代码中介绍 pg 所提供的并行查询框架的一篇文档,之后应该会再陆续输出几篇调研结果;文档在代码中的路径为 src/backend/access/transam/README.parallel,翻译如有疏漏还请各位大佬多多指正。
那如果有读者对并行算子本身没有任何概念,微扰酱这边给各位举一个简单的例子。我们考虑一个简单的 agg 语句 explain select count(*) from bmscantest2 where a>1。如果一张表内数据不多时,pg 的优化器是不会选择采用并行化的,得到的查询计划如下所示。
postgres=# explain select count(*) from bmscantest2 where a>1;
QUERY PLAN
-----------------------------------------------------------------
Aggregate (cost=1.13..1.14 rows=1 width=8)
-> Seq Scan on bmscantest2 (cost=0.00..1.12 rows=3 width=0)
Filter: (a > 1)
(3 rows)
而如果表中数据比较多,pg 可能就会开始考虑并行化的查询计划,得到的查询计划如下,其中 Workers Planned: 4 就表示我们启动了4个工作进程进行agg的计算。
postgres=*# explain select count(*) from bmscantest where a>1;
QUERY PLAN
-------------------------------------------------------------------------------------------
Finalize Aggregate (cost=1968.35..1968.36 rows=1 width=8)
-> Gather (cost=1568.33..1968.34 rows=4 width=8)
Workers Planned: 4
-> Partial Aggregate (cost=1568.33..1568.34 rows=1 width=8)
-> Parallel Seq Scan on bmscantest (cost=0.00..1547.50 rows=8333 width=0)
Filter: (a > 1)
(6 rows)
借一张 Thomas Munro 的图,出自他18年做的 Parallelism in PostgreSQL 11 的演讲的 slides。
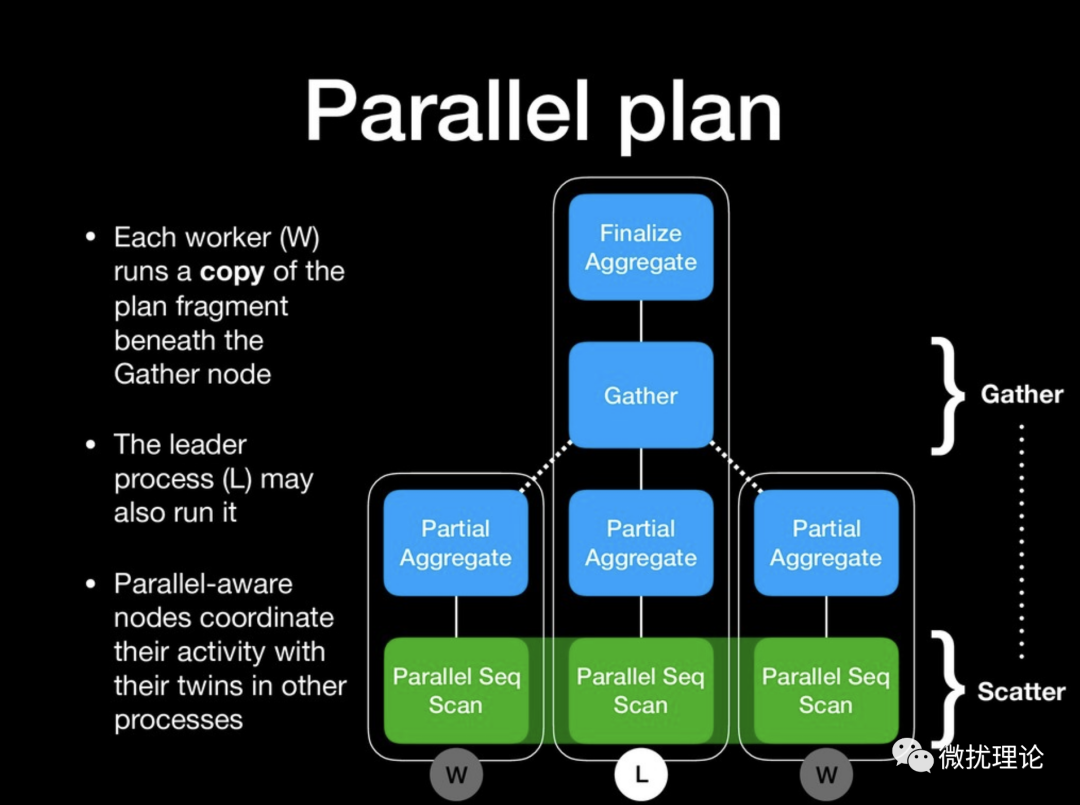
而算子的并行化具体是如何实现的,又能带来怎样的性能提升则要因算子而异,且听下回分解。
以下为文档翻译:
概述
PostgreSQL 提供了一些简单的机制使得编写并行算法更加简单。你可以通过使用 ParallelContext 数据结构去唤起后台工作进程、初始化工作进程的进程状态(以匹配唤起他们的后台进程),使进程通过动态共享内存 (Dynamic Shared Memory) 进行通信和写并不复杂的逻辑且不用意识到并行的存在就可以让代码跑在用户后台进程或者任一并行的工作进程。
那个发起并行指令的进程(我们此后称为发起进程)首先会创建一个动态共享内存区,该区域在整个并行运算的过程里都会存在。动态共享内存区会包含(1)用于传递错误信息(和通过 elog/ereport 上报的其他信息)的 shm_mq (2)用于同步工作进程状态的发起进程私有状态的序列化表示(3)任何其他 ParallelContext 使用者出于使用目的自定义的数据结构。一旦发起进程完成了动态共享内存区的初始化,它就会要求 postmaster 发起适当数量的工作进程。这些工作进程随后会连接上动态共享内存区、初始化他们的状态然后唤起入口函数,我们马上会介绍这一部分内容。
错误上报
工作进程被启动的时候,首先会绑定动态共享内存区并定位其中的 shm_mq,用于进行错误上报;工作进程会把所有的协议消息重定向给 shm_mq。而在此之前,所有后台工作进程发生的错误并不会发送给发起进程。从发起进程的视角来看,这些工作进程只不过是初始化失败了。发起进程也需要始终做好和比其发起的数量更少的工作进程协同工作的准备,所以即使出现这样的情况也不会有什么额外的问题。
当有一条消息(在消息体很大被拆分的时候也可能是部分消息)被放入错误上报队列时,PROCSIG_PARALLEL_MESSAGE 会被发送到发起进程。而发起进程的 CHECK_FOR_INTERRUPTS() 就会检查到这一事件,从而读取并重新在发起进程上重新发出该消息。大多数情况下,这就足以使得错误上报在并行的模式下可以工作了。当然,为了正常运行,发起进程需要定期执行 CHECK_FOR_INTERRUPTS() 并避免中断长时间阻塞进程,但这些事情本就是应该做的。
(目前仍有的一个悬而未决的问题就是有时候一些消息会被写到系统日志中两次,一次是在上报发生的工作进程写入,一次是在发起进程收到消息后重新抛出的消息。如果我们决定要避免其中一次的消息写入,应该想办法避免发起进程的重复写。不然的话,如果工作进程因为一些原因未能将消息传递给发起进程,则整个消息就会被丢失了。)
状态共享
在单进程状态下可以工作的 C 代码在并行模式下却失败了的情况是时有发生的。只要全局变量存在,就没有并行的框架可以完全解决这个问题。没有通用的机制可以保证每个全局变量在工作进程中可以和发起进程有一样的值。即使我们可以保证这一点,只要我们调用了一些函数去改变这些变量,那么只有在这些改变发生的进程才可以立刻看到更新后的新值。相似的问题在任何一个我们使用的更复杂的数据结构中都会出现。比如伪随机数生成器在指定随机种子的情况下,每次都应该产生同样的可预测的随机序列。而这背后依赖的是执行生成器的进程内部的私有状态,这本身不会跨进程共享。所以一个并行安全的伪随机器应该要将其状态存储在动态共享内存中,并用锁保证其安全性。而并行框架本身没有办法知道用户所调用的代码是否有这样的问题,也就没有办法对此做出什么措施。
取而代之的,我们采用了更加实用主义的策略。首先,我们试着让更多的操作在并行模式下和单进程模式下工作的一样正确。其次,我们试着通过错误检查禁止一些常见的不安全操作。这些机制可以 100% 保证 SQL 中的不安全行为被禁止,但是 C 代码中的不安全行为却可能并不会触发这些检查。这些检查会通过调用 EnterParallelMode() 函数启用。因而,在创建并行上下文的时候,我们就应该调用这个函数,并在 ExitParallelMode() 调用时解除这些检查。最后,最重要的一个限制则是我们要求所有的操作在只读的时候才可以使用并行模式,所有的写操作和 DDL 都是不会被并行的。也许以后我们可以减少这样的限制。
为了使得更多的操作可以在并行模式下安全执行,我们会从发起进程中拷贝出许多重要的状态到工作进程里,包括:
dfmgr.c 动态加载的一系列动态库。
被验证的用户 ID 和当前数据库。每个工作进程都会和发起进程用同样的 ID 连接同样的数据库。
所有 GUC 值。在并行模式下禁止任何 GUC 的永久改变;但暂时的变化,比如进入一个带有非空 proconfig 的函数,则是可以的。
当前子事务的 XID,最上层事务的 XID,以及当前的 XID 列表(即正在进行中或提交的事务)。需要这些信息以确保元组可见性检查在工作进程中与在发起进程中返回相同的结果。细节请参阅下面的事务集成部分。
CID 映射。这也是为了保证一致的元组可见性检查。需要同步这个数据结构的是我们不能支持并行模式写入的一个主要原因:因为写入可能会创建新的 CID,而我们无法让其他工作进程了解它们。
事务快照。
活跃快照,可能和事务快照不同。
当前活动的用户 ID 和安全上下文。
与阻塞的 REINDEX 操作相关的状态。这能阻止访问正在被重建的索引。
活跃的 relmapper.c 的映射状态。这是为了保证获取映射的关系表 oid 对应的 relfilenumber 一致所需要的。
为了防止在并行模式下运行时出现死锁,代码中还引入了针对主进程和工作进程的分组锁 (group locking)。具体可以参考 src/backend/storage/lmgr/README 。
事务集成
不管主进程中的 TransactionState 栈是什么样子,每个并行工作进程最终都会得到一个深度为 1 的事务状态栈。这个栈中唯一的记录会被标记为特殊的事务状态 TBLOCK_PARALLEL_INPROGRESS,这样它就不会与普通的最上层事务混淆。这个 TransactionState 的 XID 会被设置为发起进程的当前活动子事务中最里的 XID。发起进程的最上层 XID,以及所有当前(进行中或已提交)XID 与 TransactionState 堆栈分开存储,但 GetTopTransactionId()、GetTopTransactionIdIfAny() 和 TransactionIdIsCurrentTransactionId() 调用时会返回和发起进程相同的值。我们可以复制整个事务状态堆栈,但其中大部分状态是无用的:例如,你不能从工作进程中回滚到保存点,并且没有与内存上下文相关的资源或中间子事务的资源所有者。
在并行模式下不能对事务状态进行有意义的更改。既不能分配 XID,也不能发起或结束子事务,因为我们无法将这些状态更改传达或同步给协作的其他进程。在所有工作进程退出之前,发起进程想要退出正在进行的任何事务或子事务显然是不可行的;而对于工作进程来说,尝试提交子事务或中止当前子事务并自行切换上下文执行一些非当前发起进程正在处理的事务,当然是更不被允许的。允许以并行模式执行内部子事务(例如,实现 PL/pgSQL EXCEPTION 块)可能是可行的,只要它们不会产生 XID,因为其他进程实际上不需要知道这些事务的发生,也不需要为此做任何事情。但现在,我们选择直接禁用他们。
在并行操作结束时,不管是得到了成功提交还是被错误中断,与该操作关联的并行工作进程都会退出。在错误发生的情况下,发起进程的终止事务处理模块会发出终止所有剩余的工作进程的信号,然后等待他们退出。在并行操作成功的情况下,发起进程不发送任何信号,而是必须等待工作进程完成并自行退出。无论在哪种情况下,在发起进程清理被创建的(子)事务之前,都必须先等待工作进程全部退出;否则,可能会出现混乱。例如,如果发起进程正在回滚创建了某个正在被工作进程扫描的表的事务,则该表可能会在工作进程扫描它的过程中消失。这显然是不安全的。
通常,此时每个工作进程执行的清理操作类似于最顶层事务的提交或中止时发生的。每个进程都有自己的资源所有者:buffer pins、catcache 或 relcache 的引用计数、元组描述符等由每个进程独立管理,并且必须在退出之前释放它们。但是,工作进程对事务的提交或中止与真正的最顶层事务的提交或中止之间仍存在一些重要区别,包括:
不会有任何提交或终止记录被写入系统;发起进程会处理这件事。
pg_temp 命名空间的清理不会发生。并行进程不能安全的访问发起进程的 pg_temp 命名空间,也不应该创建一个自己的副本。
编码约定
在开始任何并行操作之前,调用 EnterParallelMode();在所有并行操作完成后,调用 ExitParallelMode()。试图并行化任何特定算子的时候,都请使用 ParallelContext。基本的编码模式如下所示:
EnterParallelMode(); /* prohibit unsafe state changes */
pcxt = CreateParallelContext("library_name", "function_name", nworkers);
/* Allow space for application-specific data here. */
shm_toc_estimate_chunk(&pcxt->estimator, size);
shm_toc_estimate_keys(&pcxt->estimator, keys);
InitializeParallelDSM(pcxt); /* create DSM and copy state to it */
/* Store the data for which we reserved space. */
space = shm_toc_allocate(pcxt->toc, size);
shm_toc_insert(pcxt->toc, key, space);
LaunchParallelWorkers(pcxt);
/* do parallel stuff */
WaitForParallelWorkersToFinish(pcxt);
/* read any final results from dynamic shared memory */
DestroyParallelContext(pcxt);
ExitParallelMode();
如果需要,在调用 WaitForParallelWorkersToFinish() 之后,可以重置上下文,以便可以使用相同的并行上下文重新启动新的工作进程。为此,我们需要首先调用 ReinitializeParallelDSM() 以重新初始化由并行上下文机制本身管理的状态;然后重置任何所需要的状态;之后,你就可以再次调用 LaunchParallelWorkers 去唤起新的工作进程了。
结语
PostgreSQL 确实是一个非常复杂的系统,微扰酱已经入职 Hashdata 半年,接触到的代码面积仍然是 PostgreSQL 中非常小的一部分;以至于翻译这篇文章的时候对里面共享内存机制、锁机制还有事务的机制都还仍有很多困惑,翻译出来把握也不是很足,希望好朋友们多多交流。
本文转载自微信公众号「微扰理论」,作者微扰理论 。转载本文请联系微扰理论公众号。
以上就是良许教程网为各位朋友分享的Linu系统相关内容。想要了解更多Linux相关知识记得关注公众号“良许Linux”,或扫描下方二维码进行关注,更多干货等着你 !

 微信扫一扫打赏
微信扫一扫打赏
 支付宝扫一扫打赏
支付宝扫一扫打赏

.png)

.jpg){kind=link}